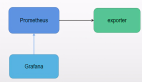
部署一套完整的 Prometheus+Grafana 智能監控告警系統
兄弟們,凌晨三點,又是運維兄弟的奪命連環 call:“哥!線上 Java 服務崩了!日志刷得飛快,根本找不到哪兒出問題!” 你揉著眼睛爬起來遠程連服務器,CPU 飆到 100%、內存滿了、JVM 堆溢出…… 一堆問題堆在眼前,可因為沒監控,連問題啥時候開始的都不知道。
這種 “兩眼一抹黑” 的崩潰時刻,我猜每個 Java 開發 / 運維都經歷過。今天咱們就來搞個 “運維救星套餐”—— 把 Prometheus+Grafana 這套監控告警系統從頭到尾搭明白,以后服務器、Java 應用的風吹草動,咱們都能提前知道,再也不用半夜被電話嚇醒!
先跟新手兄弟說句大實話:這倆工具聽著挺唬人,其實就是 “采集數據的小弟(Prometheus)” 加 “畫圖表的大哥(Grafana)”,再配上 “喊人的喇叭(Alertmanager)”。咱們一步步來,保證你看完就能上手,全程大白話,不整那些繞人的技術黑話。
一、先把 “地基” 打牢:環境準備
在搭系統前,咱們得先確認服務器環境 —— 別跟我似的,當年第一次搭的時候,服務器連 Docker 都沒裝,愣生生折騰了倆小時才發現問題。這里我分兩種情況說:Linux 服務器(生產常用)和 Windows(本地測試用),你按需取用。
1.1 服務器基礎要求
不管啥系統,至少滿足這幾點:
- 內存:2G 以上(監控 10 臺以內機器足夠,機器多就加內存,Prometheus 吃內存)
- 硬盤:20G 以上(要存監控數據,默認存 15 天,不夠再擴)
- 系統:Linux 建議 CentOS 7+/Ubuntu 18+,Windows 建議 Win10/Server 2019
- 網絡:服務器之間能互通(比如 Prometheus 要連被監控的 Java 服務,端口得開)
1.2 依賴工具安裝(重點!)
咱們用 Docker 部署,比源碼編譯簡單 10 倍,新手別頭鐵去搞源碼!先裝 Docker 和 Docker Compose(管理多容器用)。
Linux 下裝 Docker(以 CentOS 7 為例)
直接復制命令就行,記得每步跑完看一眼有沒有 “success”:
# 先卸載舊版本(防止沖突,沒裝過也沒事)
sudo yum remove docker docker-client docker-client-latest docker-common docker-latest docker-latest-logrotate docker-logrotate docker-engine
# 裝依賴
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# 設置Docker倉庫(用阿里云的,快!)
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 裝Docker
sudo yum install -y docker-ce docker-ce-cli containerd.io
# 啟動Docker并設為開機啟動
sudo systemctl start docker
sudo systemctl enable docker
# 驗證是否裝好(出現版本號就成)
docker --version然后裝 Docker Compose:
# 下載Compose(注意:如果報錯,把后面的版本號換成最新的,去官網查)
sudo curl -L "https://github.com/docker/compose/releases/download/v2.20.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
# 給權限
sudo chmod +x /usr/local/bin/docker-compose
# 驗證(出現版本號就OK)
docker-compose --versionWindows 下裝 Docker
去 Docker 官網下 “Docker Desktop”,一路下一步就行(記得勾上 “Add shortcut to desktop”)。裝完打開,等右下角圖標變綠,打開命令提示符(CMD)輸docker --version,能看到版本號就成。
這里插句嘴:Windows 家庭版可能會提示 “需要 WSL 2”,別慌,按提示去微軟商店裝個 Ubuntu,再重啟 Docker 就好了,比當年我裝雙系統簡單多了。
二、第一步:把 “數據采集員” Prometheus 架起來
Prometheus 的核心工作就是 “定期去被監控的機器 / 應用上拿數據”—— 比如每隔 10 秒查一次 Linux 的 CPU 使用率,每隔 5 秒查一次 Java 服務的堆內存。咱們先把它跑起來,再慢慢配置。
2.1 先搞個 “工作目錄”(別亂建文件夾!)
不管 Linux 還是 Windows,先建個統一的目錄,比如/opt/prometheus-grafana(Linux)或D:\prometheus-grafana(Windows),所有配置文件都放這里,以后好找。
Linux 下建目錄:
mkdir -p /opt/prometheus-grafana/{prometheus,alertmanager,grafana}
cd /opt/prometheus-grafanaWindows 下直接在 D 盤右鍵新建文件夾,命名成 “prometheus-grafana”,再里面建三個子文件夾:prometheus、alertmanager、grafana。
2.2 寫 Prometheus 的配置文件(核心!)
Prometheus 啟動靠的是prometheus.yml這個配置文件,咱們先寫個基礎版,能監控它自己就行(先確保自身能跑,再監控別的)。
在prometheus文件夾里新建prometheus.yml,內容如下(我加了詳細注釋,別復制注釋里的 #號!):
# 全局配置(所有監控任務都能用)
global:
scrape_interval: 15s # 每隔15秒采集一次數據(新手別設太短,會把服務器累死)
evaluation_interval: 15s # 每隔15秒評估一次告警規則
# 告警規則文件(后面配Alertmanager會用到,先空著)
rule_files:
# - "alert_rules.yml" # 注釋掉,后面再開
# 監控目標配置(告訴Prometheus要監控誰)
scrape_configs:
# 監控Prometheus自己(必填,先看自己活沒活)
- job_name: "prometheus" # 任務名,隨便起,好認就行
static_configs:
- targets: ["localhost:9090"] # 監控地址,localhost就是自己,端口9090是Prometheus默認端口這里插個坑:如果你的 Prometheus 是用 Docker 跑的,localhost要改成 “容器名” 或 “宿主機 IP”,別傻乎乎寫localhost,到時候監控不到還找不到原因(我當年踩過這個坑,查了半小時日志)。
2.3 用 Docker 啟動 Prometheus
咱們用 Docker Compose 來啟動,比單獨用 docker run 方便,以后重啟、停止都一鍵搞定。
在/opt/prometheus-grafana(Linux)或D:\prometheus-grafana(Windows)目錄下,新建docker-compose.yml文件,內容如下:
version: '3.8' # Compose版本,跟你裝的版本匹配就行
services:
# Prometheus服務
prometheus:
image: prom/prometheus:v2.47.0 # 用2.47.0版本,穩定!別用latest,容易出兼容問題
container_name: prometheus # 容器名,好記
restart: always # 開機自啟,服務器重啟后不用手動開
ports:
- "9090:9090" # 端口映射:宿主機9090端口 -> 容器9090端口
volumes:
# 把本地的配置文件掛載到容器里(改本地文件,容器里就生效)
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
# 把監控數據掛載到本地(防止容器刪了數據丟了)
- ./prometheus/data:/prometheus/data
command:
# 告訴Prometheus用哪個配置文件,以及數據存哪里
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/data'
- '--storage.tsdb.retention.time=15d' # 數據保留15天,夠了,多了占硬盤然后啟動!在當前目錄下執行命令:
# Linux下
docker-compose up -d
# Windows下(打開CMD,進入D:\prometheus-grafana目錄,再執行)
docker-compose up -d執行完后,輸docker ps(Linux)或在 Docker Desktop 里看,能看到prometheus容器狀態是 “Up” 就成了。
2.4 驗證 Prometheus 是否跑通
打開瀏覽器,輸入http://你的服務器IP:9090(比如 Linux 服務器 IP 是 192.168.1.100,就輸http://192.168.1.100:9090)。
能看到 Prometheus 的界面,點擊頂部 “Status”→“Targets”,如果 “prometheus” 那一行的 “State” 是 “UP”,說明沒問題!如果是 “DOWN”,別慌,先檢查端口是不是被占用了(Linux 用netstat -tuln | grep 9090,Windows 用netstat -ano | findstr 9090),再看看配置文件里的 targets 對不對。
三、第二步:給 Java 應用裝 “監控插件”(重點!)
咱們是 Java 技術號,監控 Linux 服務器只是基礎,重點是監控 Java 應用 —— 比如 Spring Boot 服務的 JVM 堆內存、GC 次數、接口響應時間這些。這時候得用 “JMX Exporter” 這個工具,它能把 Java 應用的 JVM 指標轉成 Prometheus 能認的格式。
3.1 下載 JMX Exporter
JMX Exporter 是個 JAR 包,直接從 GitHub 下載:https://github.com/prometheus/jmx_exporter/releases 。找最新的 “jmx_prometheus_javaagent-xxx.jar”,比如 “jmx_prometheus_javaagent-0.19.0.jar”。
下載后,放到被監控的 Java 應用服務器上,比如/opt/jmx-exporter(Linux)或D:\jmx-exporter(Windows)目錄下。
3.2 寫 JMX Exporter 的配置文件
在同一個目錄下,新建config.yml文件,內容如下(這個配置能監控大部分 JVM 指標,夠用了):
lowercaseOutputLabelNames: true
lowercaseOutputName: true
rules:
- pattern: 'java.lang<type=Memory><HeapMemoryUsage>(\w+):'
name: jvm_memory_heap_usage_$1
type: GAUGE
- pattern: 'java.lang<type=Memory><NonHeapMemoryUsage>(\w+):'
name: jvm_memory_nonheap_usage_$1
type: GAUGE
- pattern: 'java.lang<type=GarbageCollector, name=(\w+)><CollectionCount>:'
name: jvm_gc_collection_count_$1
type: COUNTER
- pattern: 'java.lang<type=GarbageCollector, name=(\w+)><CollectionTime>:'
name: jvm_gc_collection_time_$1
type: COUNTER
- pattern: 'java.lang<type=Threading><ThreadCount>:'
name: jvm_thread_count
type: GAUGE簡單解釋下:這個配置告訴 JMX Exporter,要把 JVM 的堆內存、非堆內存、GC 次數、線程數這些指標抓出來,起個 Prometheus 能認的名字(比如jvm_memory_heap_usage_used就是堆內存已用大小)。
3.3 給 Java 應用加啟動參數(關鍵!)
不管你的 Java 應用是用java -jar啟動,還是用 Tomcat 部署,都要加個 JVM 啟動參數,讓 JMX Exporter 跟著應用一起跑。
比如你的 Spring Boot 應用 JAR 包叫demo.jar,啟動命令就改成這樣:
# Linux下(注意路徑要對!)
java -javaagent:/opt/jmx-exporter/jmx_prometheus_javaagent-0.19.0.jar=9100:/opt/jmx-exporter/config.yml -jar demo.jar
# Windows下(路徑用反斜杠,或者雙斜杠)
java -javaagent:D:\jmx-exporter\jmx_prometheus_javaagent-0.19.0.jar=9100:D:\jmx-exporter\config.yml -jar demo.jar這里的9100是 JMX Exporter 的端口,以后 Prometheus 就從這個端口拿 Java 應用的指標。記住這個端口,后面要用到!啟動后,驗證一下:用瀏覽器訪問http://Java應用服務器IP:9100/metrics,能看到一堆以jvm_開頭的指標,就說明 JMX Exporter 跑通了。
3.4 讓 Prometheus 監控 Java 應用
回到 Prometheus 的prometheus.yml文件,在scrape_configs里加一個監控任務:
scrape_configs:
# 原來的prometheus監控任務保留
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
# 新增:監控Java應用
- job_name: "java_app" # 任務名,叫java_app好認
static_configs:
# 這里填Java應用服務器的IP和JMX Exporter的端口,多個應用用逗號分隔
- targets: ["192.168.1.101:9100", "192.168.1.102:9100"]
scrape_interval: 10s # Java應用指標變化快,采集間隔設短點,10秒一次改完配置文件后,重啟 Prometheus 讓配置生效:
# Linux下(在docker-compose.yml所在目錄)
docker-compose restart prometheus
# Windows下同理
docker-compose restart prometheus再去 Prometheus 的 Targets 頁面(http:// 服務器 IP:9090/targets),能看到 “java_app” 任務下的目標狀態是 “UP”,就說明 Prometheus 能拿到 Java 應用的指標了!這里再插個坑:如果是云服務器(比如阿里云、騰訊云),要在安全組里開 9100 端口,不然 Prometheus 連不上 —— 我之前幫朋友搭的時候,查了一小時才發現是安全組沒開,血的教訓!
四、第三步:用 Grafana 把數據 “畫成畫”(可視化核心)
Prometheus 采集的數據是一堆文字,看著頭疼 ——Grafana 就是來解決這個問題的,它能把文字轉成漂亮的圖表,比如 CPU 使用率曲線、JVM 內存餅圖,一眼就能看出問題。
4.1 用 Docker 啟動 Grafana
還是在docker-compose.yml里加 Grafana 的配置,完整的docker-compose.yml現在長這樣:
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.47.0
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/data:/prometheus/data
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/data'
- '--storage.tsdb.retention.time=15d'
# 新增Grafana服務
grafana:
image: grafana/grafana:10.1.2 # 10.x版本穩定,界面也好看
container_name: grafana
restart: always
ports:
- "3000:3000" # Grafana默認端口3000
volumes:
# 掛載數據目錄,防止容器刪了配置丟了
- ./grafana/data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=123456 # 管理員密碼,第一次登錄用,后面可以改
- GF_USERS_ALLOW_SIGN_UP=false # 禁止注冊,防止別人亂注冊
depends_on:
- prometheus # 先啟動Prometheus,再啟動Grafana然后啟動 Grafana(如果之前已經啟動了 Prometheus,直接執行這個命令就行):
docker-compose up -d啟動后,用瀏覽器訪問http://服務器IP:3000,第一次登錄用戶名是admin,密碼是剛才配置的123456,登錄后會讓你改密碼,改成自己好記的(別用 123456,生產環境要復雜點)。
4.2 給 Grafana 加 Prometheus 數據源
Grafana 要畫圖,得先知道數據從哪兒來 —— 也就是把 Prometheus 設為數據源。
步驟如下(跟著點就行,很簡單):
- 登錄后,點擊左側 “Configuration”(齒輪圖標)→“Data Sources”;
- 點擊 “Add data source”,搜索 “Prometheus”,選中它;
- 在 “HTTP”→“URL” 里填http://prometheus:9090(因為用 Docker Compose,容器間能通過容器名訪問,不用寫 IP);
- 其他默認,拉到最下面點擊 “Save & Test”,出現 “Data source is working” 就成了!
這里再插個坑:如果你的 Grafana 和 Prometheus 不在同一臺服務器,URL 要填http://Prometheus服務器IP:9090,還要確保兩臺服務器能通 9090 端口。
4.3 導入現成的 Dashboard(不用自己畫!)
Grafana 有個 “Dashboard 市場”,里面有無數現成的圖表模板,咱們不用自己從零開始畫,直接導入就行,省時間還專業。
4.3.1 導入 Linux 服務器監控 Dashboard
先搞個 Linux 監控的,看服務器 CPU、內存、磁盤這些。
- 打開 Grafana,左側點擊 “Dashboards”→“Browse”;
- 點擊右上角 “Import”,在 “Import via grafana.com” 里輸入模板 ID:8919(這個是官方推薦的 Linux 監控模板,超全);
- 點擊 “Load”,然后在 “Data source” 里選擇咱們剛才加的 “Prometheus”,點擊 “Import”;
- 搞定!現在能看到 Linux 服務器的 CPU 使用率、內存使用率、磁盤 IO、網絡流量這些圖表,實時更新,賊直觀。
4.3.2 導入 Java 應用監控 Dashboard
重點來了,Java 應用的 JVM 監控模板,用這個 ID:4701(這個模板能監控堆內存、非堆內存、GC 次數、線程數,Java 開發者必備)。
- 同樣點擊 “Import”,輸入4701,點擊 “Load”;
- 選擇 Prometheus 數據源,點擊 “Import”;
- 現在能看到 Java 應用的 JVM 堆內存使用情況、GC 時間、線程數這些關鍵指標了!比如 “JVM Heap Memory Usage” 圖表,能清楚看到堆內存的已用、空閑、最大大小,再也不用靠jstat命令看一堆數字了。
這里給個小技巧:把常用的 Dashboard 設為 “Home Dashboard”,下次登錄直接看。方法是:打開 Dashboard,點擊右上角 “Star”(星標),然后點擊左側 “Dashboards”→“Home”,就能看到了。
五、第四步:搭告警系統(有問題早通知!)
光監控還不夠,得有問題的時候主動通知咱們 —— 比如 CPU 超過 80%、Java 應用堆內存超過 90%,這時候 Alertmanager 就要上場了,它能把 Prometheus 的告警信息發給郵件、釘釘、企業微信。
5.1 啟動 Alertmanager
先在docker-compose.yml里加 Alertmanager 的配置,完整文件如下:
version: '3.8'
services:
prometheus:
image: prom/prometheus:v2.47.0
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert_rules.yml:/etc/prometheus/alert_rules.yml # 新增告警規則文件
- ./prometheus/data:/prometheus/data
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus/data'
- '--storage.tsdb.retention.time=15d'
depends_on:
- alertmanager # 先啟動Alertmanager
grafana:
image: grafana/grafana:10.1.2
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana
environment:
- GF_SECURITY_ADMIN_PASSWORD=123456
- GF_USERS_ALLOW_SIGN_UP=false
depends_on:
- prometheus
# 新增Alertmanager服務
alertmanager:
image: prom/alertmanager:v0.26.0
container_name: alertmanager
restart: always
ports:
- "9093:9093" # Alertmanager默認端口9093
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml # 告警配置文件
command:
- '--config.file=/etc/alertmanager/alertmanager.yml'5.2 寫 Alertmanager 配置文件(以郵件告警為例)
在alertmanager文件夾里新建alertmanager.yml文件,內容如下(我用 QQ 郵箱舉例,其他郵箱類似):
global:
# 郵件配置
smtp_smarthost: 'smtp.qq.com:465' # QQ郵箱SMTP服務器,端口465(SSL)
smtp_from: '你的QQ郵箱@qq.com' # 發件人郵箱
smtp_auth_username: '你的QQ郵箱@qq.com' # 用戶名
smtp_auth_password: '你的QQ郵箱授權碼' # 不是QQ密碼!是授權碼,去QQ郵箱設置里開
smtp_require_tls: false # QQ郵箱SSL不用TLS,設為false
# 路由配置(告警往哪兒發)
route:
group_by: ['alertname'] # 按告警名分組,比如同是CPU告警的放一組
group_wait: 10s # 組內第一個告警觸發后,等10秒再發,防止頻繁告警
group_interval: 1m # 同一組告警,每隔1分鐘發一次
repeat_interval: 1h # 同一告警,1小時內只發一次,避免刷屏
receiver: 'email_receiver' # 默認發給email_receiver這個接收器
# 接收器配置(誰接收告警)
receivers:
- name: 'email_receiver'
email_configs:
- to: '接收人郵箱@xxx.com' # 比如你的工作郵箱
send_resolved: true # 問題解決后,發“已恢復”的通知
# 抑制規則(避免重復告警)
inhibit_rules:
- source_match:
severity: 'critical' # 當有緊急告警時
target_match:
severity: 'warning' # 抑制警告級別的告警
equal: ['alertname', 'instance'] # 按告警名和實例名匹配這里重點說下 QQ 郵箱授權碼怎么弄:
- 登錄 QQ 郵箱,點擊頂部 “設置”→“賬戶”;
- 拉到 “POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV 服務”,開啟 “IMAP/SMTP 服務”;
- 點擊 “生成授權碼”,用手機掃碼,得到的字符串就是smtp_auth_password,別填 QQ 密碼!
5.3 寫 Prometheus 告警規則
在prometheus文件夾里新建alert_rules.yml文件,定義什么時候觸發告警。咱們寫幾個常用的規則:
groups:
- name: 服務器監控告警
rules:
# 1. CPU使用率超過80%,持續5分鐘
- alert: 服務器CPU使用率過高
expr: 100 - (avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance) * 100) > 80
for: 5m
labels:
severity: warning # 告警級別:warning(警告)、critical(緊急)
annotations:
summary: "服務器{{ $labels.instance }} CPU使用率過高"
description: "服務器{{ $labels.instance }} CPU使用率已超過80%,當前值:{{ $value | round 2 }}%,已持續5分鐘"
# 2. 內存使用率超過90%,持續5分鐘
- alert: 服務器內存使用率過高
expr: 100 - (node_memory_Available_bytes / node_memory_Total_bytes * 100) > 90
for: 5m
labels:
severity: critical
annotations:
summary: "服務器{{ $labels.instance }} 內存使用率過高"
description: "服務器{{ $labels.instance }} 內存使用率已超過90%,當前值:{{ $value | round 2 }}%,已持續5分鐘"
- name: Java應用監控告警
rules:
# 3. Java堆內存使用率超過90%,持續3分鐘
- alert: Java應用堆內存使用率過高
expr: jvm_memory_heap_usage_used / jvm_memory_heap_usage_max * 100 > 90
for: 3m
labels:
severity: critical
annotations:
summary: "Java應用{{ $labels.instance }} 堆內存使用率過高"
description: "Java應用{{ $labels.instance }} 堆內存使用率已超過90%,當前值:{{ $value | round 2 }}%,已持續3分鐘"
# 4. Java線程數超過200,持續3分鐘
- alert: Java應用線程數過多
expr: jvm_thread_count > 200
for: 3m
labels:
severity: warning
annotations:
summary: "Java應用{{ $labels.instance }} 線程數過多"
description: "Java應用{{ $labels.instance }} 線程數已超過200,當前值:{{ $value | round 0 }},已持續3分鐘"簡單解釋下:
- expr:告警觸發的條件,比如jvm_memory_heap_usage_used / jvm_memory_heap_usage_max * 100 > 90就是堆內存使用率超過 90%;
- for:持續多久才觸發告警,避免瞬時峰值誤報;
- annotations:告警內容,{{ $labels.instance }}是被監控的實例 IP,{{ $value }}是當前指標值。
5.4 讓 Prometheus 用告警規則和 Alertmanager
回到prometheus.yml文件,修改兩處:
- 打開rule_files,指定告警規則文件;
- 加alerting配置,告訴 Prometheus 告警發給 Alertmanager。
修改后的prometheus.yml如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
# 打開告警規則文件
rule_files:
- "alert_rules.yml"
# 新增:告訴Prometheus Alertmanager的地址
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"] # Docker Compose用容器名訪問
scrape_configs:
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
- job_name: "java_app"
static_configs:
- targets: ["192.168.1.101:9100", "192.168.1.102:9100"]
scrape_interval: 10s
# 新增:監控Linux服務器(需要裝node_exporter,下面說)
- job_name: "linux_server"
static_configs:
- targets: ["192.168.1.100:9100", "192.168.1.101:9100"]
scrape_interval: 15s這里注意:監控 Linux 服務器需要裝node_exporter(和 JMX Exporter 類似,采集 Linux 系統指標),步驟很簡單:
- 下載 node_exporter:https://github.com/prometheus/node_exporter/releases ;
- 解壓后啟動:./node_exporter(默認端口 9100);
- 加到 Prometheus 的 scrape_configs 里,就像上面的 “linux_server” 任務。
5.5 測試告警是否生效
咱們手動觸發一個告警來測試,比如把 Linux 服務器的 CPU 使用率打滿:
# Linux下執行這個命令,會讓CPU使用率飆升
stress --cpu 4 --timeout 60s然后等 5 分鐘(因為告警規則里for:5m),如果配置沒問題,你會收到郵件告警,內容里會寫清楚哪個服務器、CPU 使用率多少、持續了多久。問題解決后(stress 命令結束),還會收到 “已恢復” 的郵件。也可以在 Alertmanager 的界面看告警狀態:訪問http://服務器IP:9093,能看到當前的告警和歷史告警。
六、進階優化:讓監控系統更穩、更高效
到這里,基礎的監控告警系統已經搭好了,但生產環境用還得優化一下,比如數據存更久、支持更多機器、防止單點故障。
6.1 存儲優化:數據存更久,不占滿硬盤
Prometheus 默認存 15 天數據,要是想存 30 天,改docker-compose.yml里的--storage.tsdb.retention.time=30d就行。如果數據量很大,比如監控 100 臺機器,建議用遠程存儲,比如 InfluxDB 或 Thanos,把數據存在專門的數據庫里,Prometheus 只負責采集。
6.2 性能優化:減少資源占用
- 調整 scrape 間隔:不是所有指標都要 10 秒采一次,比如磁盤使用率 1 分鐘采一次就行,在 scrape_configs 里加scrape_interval: 60s;
- 過濾無用指標:用relabel_configs過濾掉不需要的指標,比如 Java 應用的某些冷門 JVM 指標,減少數據量。示例:
- job_name: "java_app"
static_configs:
- targets: ["192.168.1.101:9100"]
# 過濾掉jvm_memory_pool_開頭的指標
relabel_configs:
- source_labels: [__name__]
regex: 'jvm_memory_pool_.*'
action: drop6.3 高可用:防止 Prometheus 掛了
生產環境不能只有一個 Prometheus,萬一它掛了,整個監控就廢了。可以搞主從架構:
- 部署兩個 Prometheus,一個主(負責采集和告警),一個從(只采集,備用);
- 用 Consul 或 etcd 做服務發現,自動發現被監控的目標;
- 當主 Prometheus 掛了,從的自動接管,保證監控不中斷。
七、總結:從 0 到 1 的監控系統搭建之路
咱們從環境準備到最后優化,把 Prometheus+Grafana+Alertmanager 這套監控告警系統完整搭了一遍,核心流程其實就三步:
- Prometheus 采集數據(用 JMX Exporter/node_exporter);
- Grafana 可視化數據(導入現成 Dashboard);
- Alertmanager 發送告警(郵件 / 釘釘 / 企業微信)。
現在你再遇到線上 Java 服務出問題,不用再半夜瞎摸 —— 打開 Grafana 看圖表,能快速定位是 CPU 高了、內存滿了還是 GC 頻繁;告警郵件會提前通知你,把問題扼殺在萌芽里。