














Llama模仿Diffusion多模態漲分30%!不卷數據不燒卡,只需共享注意力分布
這次不是卷參數、卷算力,而是卷“跨界學習”——
讓Stable Diffusion當老師,教多模態大模型(如Llama-3.2)如何“看圖說話”!
性能直接飆升30%。
中國研究員聯合DeepMind團隊的最新研究《Lavender: Diffusion Instruction Tuning》,通過簡單的“注意力對齊”,僅需1天訓練、2.5%常規數據量,即可讓Llama-3.2等模型在多模態問答任務中性能飆升30%,甚至能防“偏科”(分布外醫學任務提升68%)。
且代碼、模型、訓練數據將全部開源!

下面具體來看。
模仿Stable Diffusion的交叉注意力機制
當前遇到的問題是:
傳統多模態大模型(VLM)的“視覺課”總不及格?數據不夠、過擬合、細節抓不準……像極了考前突擊失敗的學渣。

對此,團隊提出了新的解決方案:
讓Stable Diffusion這位“圖像生成課代表”,直接共享它的“學霸筆記”——注意力分布。
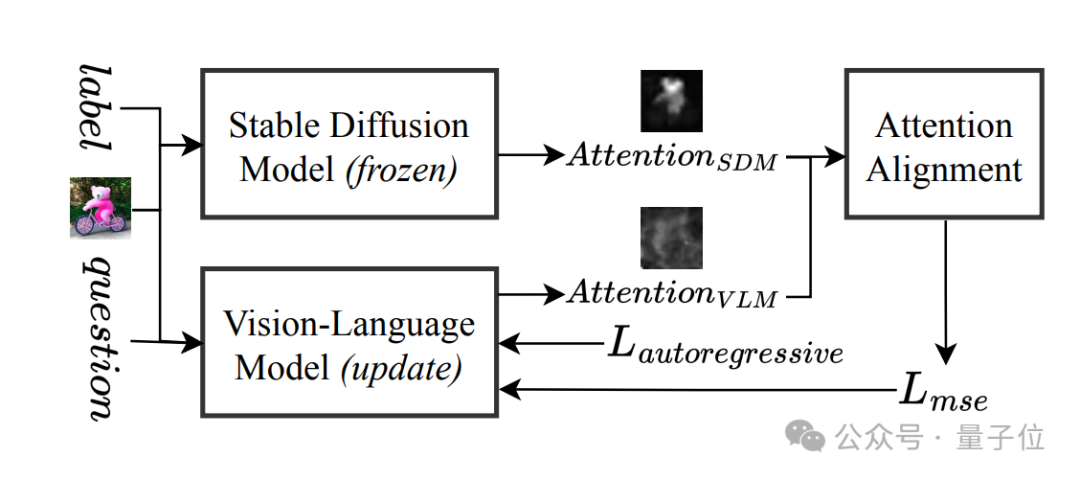
展開來說,其跨界教學可分為三步走:
Step1:拜師學藝。VLM(如Llama-3.2)向Stable Diffusion學習如何“看圖”,通過輕量級對齊網絡(Aligner)模仿其交叉注意力機制。
Step2:高效補課:僅用13萬樣本(常規數據量的2.5%)、8塊GPU訓練1天,不卷數據不燒卡。
Step3:防偏科秘籍。引入LoRA技術“輕裝上陣”,保留原模型能力的同時,專攻薄弱環節。

然后來看下具體效果。
從論文曬出的成績單來看,在16項視覺-語言任務中,Lavender調教后的Llama-3.2,性能大有提升——
在預算有限的小模型賽道上,超過SOTA(當前最優模型)50%。
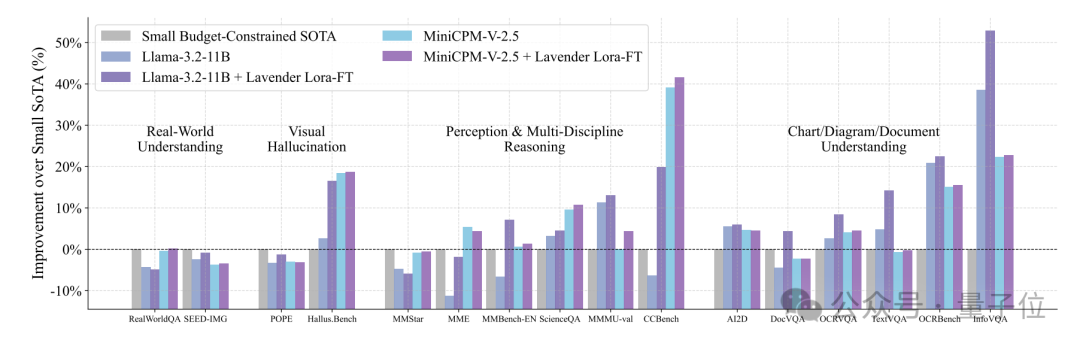
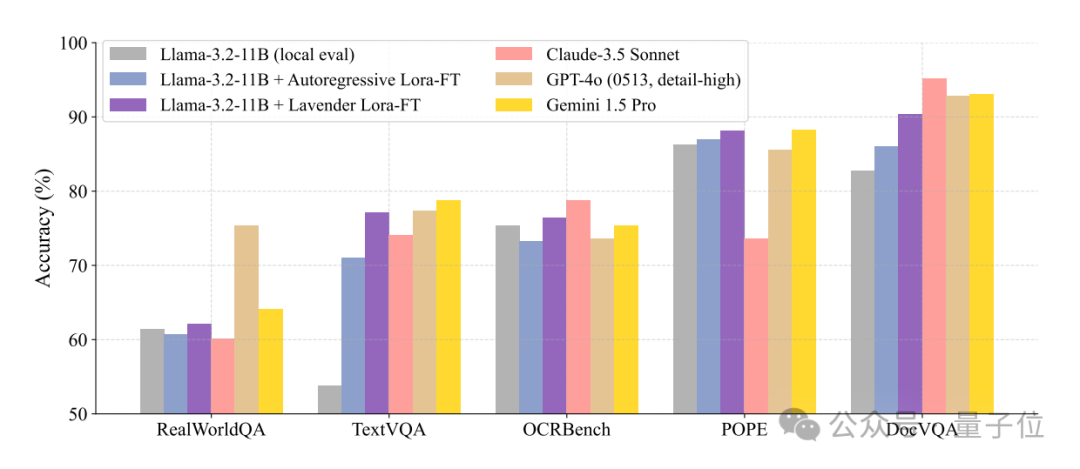
在超大模型圈子里,Lavender調教的Llama-3.2-11B居然能和那些“巨無霸”SOTA打得有來有回。
要知道,這些對手的體量一般在它的10倍以上。
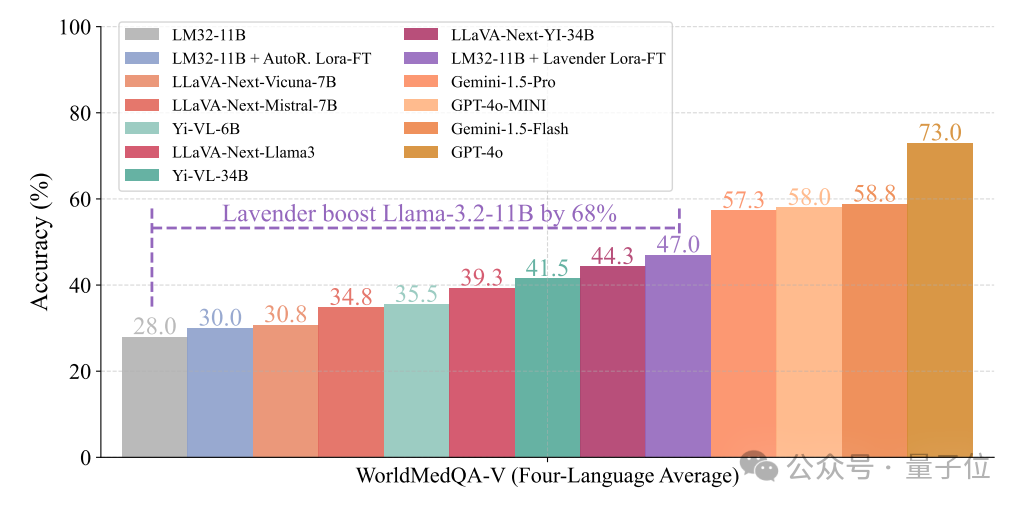
更令人驚訝的是,Lavender連醫學數據都沒“補習”,就直接讓Llama-3.2-11B在WorldMedQA這個“超綱考試”中成績暴漲68%。
具體分數見圖表(柱狀圖已標出)
代碼/模型/訓練數據全開源
小結一下,新研究主要技術亮點如下:
1、注意力對齊:Stable Diffusion的“獨家教案”
傳統VLM的注意力機制像“散光患者”,而Stable Diffusion的注意力分布則是“高清顯微鏡”。Lavender通過MSE損失函數,讓VLM學會Stable Diffusion的“聚焦技巧”,直接提升視覺理解精度。
2. 數據不夠?知識蒸餾來湊
無需海量標注數據,直接從圖像生成模型中蒸餾視覺知識,堪稱“小樣本學習神器”。正如論文團隊調侃:“這大概就是AI界的‘名師一對一補習班’。”
3. 防過擬合Buff:LoRA+注意力約束
通過低秩適配(LoRA)鎖定核心參數,避免模型“死記硬背”。實驗顯示,Lavender在分布外任務上的魯棒性吊打傳統SFT方法,具備“抗偏科體質”。
另外,從具體應用場景來看,Lavender的視覺理解能力直接拉滿。
無論是表格標題還是圖表里的小數據點,Lavender都能一眼鎖定關鍵信息,不會“偏題”;且對于復雜圖形、大小位置關系,Lavender也能避免視覺誤導,輕松拿捏。
實驗顯示,從醫學病灶定位到多語言問答,Lavender不僅看得準,還答得對,連西班牙語提問都難不倒它。

目前,團隊不僅公開了論文,代碼/模型/訓練數據也全部開源了。
- 訓練數據:由Stable Diffusion標注的高質量對齊樣本;
- 預訓練模型:基于Llama-3.2、MiniCPMv2.5等架構的Lavender適配版;
- 調參指南:從小白到進階的“注意力對齊”實操手冊;
對于上述研究,團隊負責人表示:
我們希望證明,高效、輕量的模型優化,比無腦堆參數更有未來。

























