














CMU聯(lián)手Adobe:GAN模型迎來預(yù)訓(xùn)練時代,僅需1%的訓(xùn)練樣本
進(jìn)入預(yù)訓(xùn)練時代后,視覺識別模型的性能得到飛速發(fā)展,但圖像生成類的模型,比如生成對抗網(wǎng)絡(luò)GAN似乎掉隊了。
通常GAN的訓(xùn)練都是以無監(jiān)督的方式從頭開始訓(xùn)練,費時費力不說,大型預(yù)訓(xùn)練通過大數(shù)據(jù)學(xué)習(xí)到的「知識」都沒有利用上,豈不是很虧?
而且圖像生成本身就需要能夠捕捉和模擬真實世界視覺現(xiàn)象中的復(fù)雜統(tǒng)計數(shù)據(jù),不然生成出來的圖片不符合物理世界規(guī)律,直接一眼鑒定為「假」。

預(yù)訓(xùn)練模型提供知識、GAN模型提供生成能力,二者強(qiáng)強(qiáng)聯(lián)合,多是一件美事!
問題來了,哪些預(yù)訓(xùn)練模型、以及如何結(jié)合起來才能改善GAN模型的生成能力?
最近來自CMU和Adobe的研究人員在CVPR 2022發(fā)表了一篇文章,通過「選拔」的方式將預(yù)訓(xùn)練模型與GAN模型的訓(xùn)練相結(jié)合。

論文鏈接:https://arxiv.org/abs/2112.09130
項目鏈接:https://github.com/nupurkmr9/vision-aided-gan
視頻鏈接:https://www.youtube.com/watch?v=oHdyJNdQ9E4
GAN模型的訓(xùn)練過程由一個判別器和一個生成器組成,其中判別器用來學(xué)習(xí)區(qū)分真實樣本和生成樣本的相關(guān)統(tǒng)計數(shù)據(jù),而生成器的目標(biāo)則是讓生成的圖像與真實分布盡可能相同。
理想情況下,判別器應(yīng)當(dāng)能夠測量生成圖像和真實圖像之間的分布差距。
但在數(shù)據(jù)量十分有限的情況下,直接上大規(guī)模預(yù)訓(xùn)練模型作為判別器,非常容易導(dǎo)致生成器被「無情碾壓」,然后就「過擬合」了。
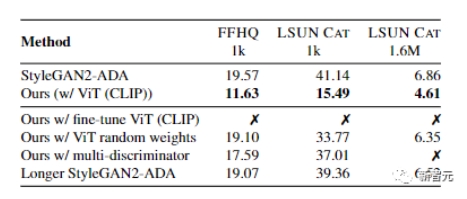
通過在FFHQ 1k數(shù)據(jù)集上的實驗來看,即使采用最新的可微分?jǐn)?shù)據(jù)增強(qiáng)方法,判別器仍然會過擬合,訓(xùn)練集性能很強(qiáng),但在驗證集上表現(xiàn)得很差。

此外,判別器可能會關(guān)注那些人類無法辨別但對機(jī)器來說很明顯的偽裝。
為了平衡判別器和生成器的能力,研究人員提出將一組不同的預(yù)訓(xùn)練模型的表征集合起來作為判別器。
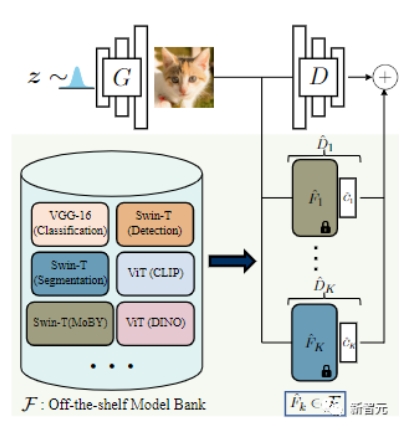
這種方法有兩個好處:
1、在預(yù)訓(xùn)練的特征上訓(xùn)練一個淺層分類器是使深度網(wǎng)絡(luò)適應(yīng)小規(guī)模數(shù)據(jù)集的常見方法,同時可以減少過擬合。
也就是說只要把預(yù)訓(xùn)練模型的參數(shù)固定住,再在頂層加入輕量級的分類網(wǎng)絡(luò)就可以提供穩(wěn)定的訓(xùn)練過程。
比如上面實驗中的Ours曲線,可以看到驗證集的準(zhǔn)確率相比StyleGAN2-ADA要提升不少。
2、最近也有一些研究證明了,深度網(wǎng)絡(luò)可以捕獲有意義的視覺概念,從低級別的視覺線索(邊緣和紋理)到高級別的概念(物體和物體部分)都能捕獲。
建立在這些特征上的判別器可能更符合人類的感知能力。
并且將多個預(yù)訓(xùn)練模型組合在一起后,可以促進(jìn)生成器在不同的、互補(bǔ)的特征空間中匹配真實的分布。
為了選擇效果最好的預(yù)訓(xùn)練網(wǎng)絡(luò),研究人員首先搜集了多個sota模型組成一個「模型銀行」,包括用于分類的VGG-16,用于檢測和分割的Swin-T等。
然后基于特征空間中真實和虛假圖像的線性分割,提出一個自動的模型搜索策略,并使用標(biāo)簽平滑和可微分的增強(qiáng)技術(shù)來進(jìn)一步穩(wěn)定模型訓(xùn)練,減少過擬合。
具體來說,就是將真實訓(xùn)練樣本和生成的圖像的并集分成訓(xùn)練集和驗證集。
對于每個預(yù)訓(xùn)練的模型,訓(xùn)練一個邏輯線性判別器來分類樣本是來自真實樣本還是生成的,并在驗證分割上使用「負(fù)二元交叉熵?fù)p失」測量分布差距,并返回誤差最小的模型。
一個較低的驗證誤差與更高的線性探測精度相關(guān),表明這些特征對于區(qū)分真實樣本和生成的樣本是有用的,使用這些特征可以為生成器提供更有用的反饋。
研究人員我們用FFHQ和LSUN CAT數(shù)據(jù)集的1000個訓(xùn)練樣本對GAN訓(xùn)練進(jìn)行了經(jīng)驗驗證。
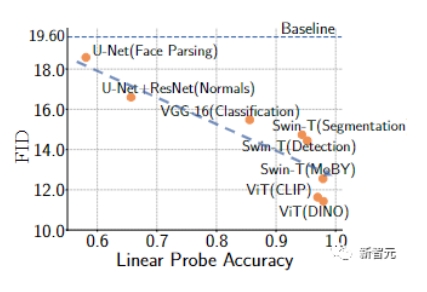
 結(jié)果顯示,用預(yù)訓(xùn)練模型訓(xùn)練的GAN具有更高的線性探測精度,一般來說,可以實現(xiàn)更好的FID指標(biāo)。
結(jié)果顯示,用預(yù)訓(xùn)練模型訓(xùn)練的GAN具有更高的線性探測精度,一般來說,可以實現(xiàn)更好的FID指標(biāo)。
為了納入多個現(xiàn)成模型的反饋,文中還探索了兩種模型選擇和集成策略
1)K-fixed模型選擇策略,在訓(xùn)練開始時選擇K個最好的現(xiàn)成模型并訓(xùn)練直到收斂;
2)K-progressive模型選擇策略,在固定的迭代次數(shù)后迭代選擇并添加性能最佳且未使用的模型。
實驗結(jié)果可以發(fā)現(xiàn),與K-fixed策略相比,progressive的方式具有更低的計算復(fù)雜度,也有助于選擇預(yù)訓(xùn)練的模型,從而捕捉到數(shù)據(jù)分布的不同。例如,通過progressive策略選擇的前兩個模型通常是一對自監(jiān)督和監(jiān)督模型。
文章中的實驗主要以progressive為主。
最終的訓(xùn)練算法首先訓(xùn)練一個具有標(biāo)準(zhǔn)對抗性損失的GAN。

 給定一個基線生成器,可以使用線性探測搜索到最好的預(yù)訓(xùn)練模型,并在訓(xùn)練中引入損失目標(biāo)函數(shù)。
給定一個基線生成器,可以使用線性探測搜索到最好的預(yù)訓(xùn)練模型,并在訓(xùn)練中引入損失目標(biāo)函數(shù)。
在K-progressive策略中,在訓(xùn)練了與可用的真實訓(xùn)練樣本數(shù)量成比例的固定迭代次數(shù)后,把一個新的視覺輔助判別器被添加到前一階段具有最佳訓(xùn)練集FID的快照中。
在訓(xùn)練過程中,通過水平翻轉(zhuǎn)進(jìn)行數(shù)據(jù)增強(qiáng),并使用可微分的增強(qiáng)技術(shù)和單側(cè)標(biāo)簽平滑作為正則化項。
還可以觀察到,只使用現(xiàn)成的模型作為判別器會導(dǎo)致散度(divergence),而原始判別器和預(yù)訓(xùn)練模型的組合則可以改善這一情況。
最終實驗展示了在FFHQ、LSUN CAT和LSUN CHURCH數(shù)據(jù)集的訓(xùn)練樣本從1k到10k變化時的結(jié)果。
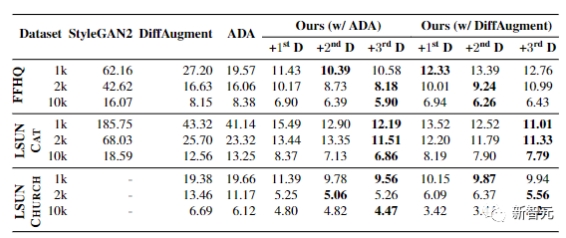
 在所有設(shè)置中,F(xiàn)ID都能獲得顯著提升,證明了該方法在有限數(shù)據(jù)場景中的有效性。
在所有設(shè)置中,F(xiàn)ID都能獲得顯著提升,證明了該方法在有限數(shù)據(jù)場景中的有效性。
為了定性分析該方法和StyleGAN2-ADA之間的差異,根據(jù)兩個方法生成的樣本質(zhì)量來看,文中提出的新方法能夠提高最差樣本的質(zhì)量,特別是對于FFHQ和LSUN CAT

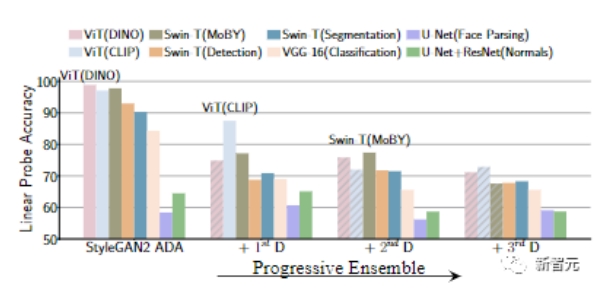
 當(dāng)我們逐步增加下一個判別器時,可以看到線性探測對預(yù)訓(xùn)練模型的特征的準(zhǔn)確性在逐漸下降,也就是說生成器更強(qiáng)了。
當(dāng)我們逐步增加下一個判別器時,可以看到線性探測對預(yù)訓(xùn)練模型的特征的準(zhǔn)確性在逐漸下降,也就是說生成器更強(qiáng)了。
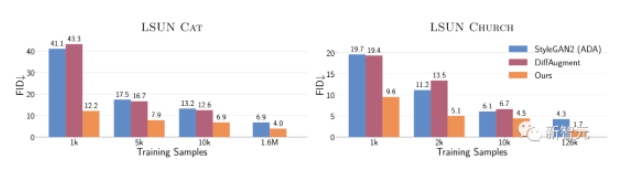
 總的來說,在只有1萬個訓(xùn)練樣本的情況下,該方法在LSUN CAT上的FID與在160萬張圖像上訓(xùn)練的StyleGAN2性能差不多。
總的來說,在只有1萬個訓(xùn)練樣本的情況下,該方法在LSUN CAT上的FID與在160萬張圖像上訓(xùn)練的StyleGAN2性能差不多。
 而在完整的數(shù)據(jù)集上,該方法在LSUN的貓、教堂和馬的類別上提高了1.5到2倍的FID。
而在完整的數(shù)據(jù)集上,該方法在LSUN的貓、教堂和馬的類別上提高了1.5到2倍的FID。

?
作者Richard Zhang在加州大學(xué)伯克利分校獲得了博士學(xué)位,在康奈爾大學(xué)獲得了本科和碩士學(xué)位。主要研究興趣包括計算機(jī)視覺、機(jī)器學(xué)習(xí)、深度學(xué)習(xí)、圖形和圖像處理,經(jīng)常通過實習(xí)或大學(xué)與學(xué)術(shù)研究人員合作。

 作者Jun-Yan Zhu是卡內(nèi)基梅隆大學(xué)計算機(jī)科學(xué)學(xué)院的機(jī)器人學(xué)院的助理教授,同時在計算機(jī)科學(xué)系和機(jī)器學(xué)習(xí)部門任職,主要研究領(lǐng)域包括計算機(jī)視覺、計算機(jī)圖形學(xué)、機(jī)器學(xué)習(xí)和計算攝影。
作者Jun-Yan Zhu是卡內(nèi)基梅隆大學(xué)計算機(jī)科學(xué)學(xué)院的機(jī)器人學(xué)院的助理教授,同時在計算機(jī)科學(xué)系和機(jī)器學(xué)習(xí)部門任職,主要研究領(lǐng)域包括計算機(jī)視覺、計算機(jī)圖形學(xué)、機(jī)器學(xué)習(xí)和計算攝影。
在加入CMU之前,他曾是Adobe Research的研究科學(xué)家。本科畢業(yè)于清華大學(xué),博士畢業(yè)于加州大學(xué)伯克利分校,然后在MIT CSAIL做博士后。

?
 ?
?




























