














數倉建模—寬表的設計
- 寬表的設計
- 為什么要建設寬表
- 寬表的好處和不足
- 如何設計寬表
- 總結
寬表的設計
其實寬表是數倉里面非常重要的一塊,前面我們介紹過了維度表事實表,今天我們介紹一下寬表,前面我們說過了數倉是分層的,這是技術進步和時代變化相結合的產物,數倉的分層式為了更好地管理數倉以及更加高效地進行數據開發。
寬表主要出現在dwd 層和報表層,當然有的人說dws 層也有,寬表,從字面意義上講就是字段比較多的數據庫表,通常情況下是將很多相關的數據包括維度表、實時、已有的指標或者是dws/dwd 表關聯在一起形成的一張數據表。
由于把不同的內容都放在同一張表存儲,寬表已經不符合范式設計的模型設計規范而且數倉里面也不強調范式設計,隨之帶來的就是數據的大量冗余,與之相對應的好處就是查詢性能的提高與便捷。
分層 請參考 數倉建模—分層建設理論
設計 請參考 數倉建模—建模方法論
為什么要建設寬表
就像我們前面說過分層的目的是為了管理方便、開發高效、問題定位、節約資源等等,那么我們建設寬表呢?前面學習建模方法論的時候,提到過維度模型的非強范式的,可以更好的利用大數據處理框架的處理能力,避免范式操作的過多關聯操作,可以實現高度的并行化。數據倉庫大多數時候是比較適合使用星型模型構建底層數據Hive表,通過大量的冗余來提升查詢效率,星型模型對OLAP的分析引擎支持比較友好,這一點在Kylin中比較能體現。
可以更好的發揮大數據框架的能力
維度模型可以更好地利用大數據框架,體現在哪里的,體現在數據數據冗余,可以避免很多的關聯,怎么體現的呢,寬表。但是這只是站在大數據框架層面上的理解,還有其他層面上的理解。
可以提高開發效率
一般情況下,我們的寬表包含了很多相關的數據,如果我們在寬表的基礎上做一些開發,那就很方便,我們直接從寬表里面取數據,避免了我們從頭計算,你設想一下你要是沒次都從ods開發一張報表,那是多痛苦的體驗啊。
可以提高數據質量
寬表的準確性,一般都是經歷了時間的檢驗的,邏輯錯誤的可能性很小,可以直接使用,要是讓你從頭開發,那這個過程中可能因為對業務理解不透徹或者是書寫的邏輯不正確,導致有數據質量問題
可以統一指標口徑
其實這一點和上面一點有點重復,但是這兩點的強調的方面是不一樣的,因為如果我們的報表要是都能從我們的底層寬表出,那么我們報表上的指標肯定是一樣的,其實這一點我相信很多人都深有體會,同一個指標的口徑不一致,導致我們提供的數據在不同的出口不一樣,是業務部門經常提出的一個問題。其實這也就是我們一直強調的核心邏輯下沉的原因。
寬表的好處和不足
寬表的好處就是我們前面提到過的我們為什么要建設寬表的原因,接下來我們看一下寬表的不足
性能不高
因為我們的寬表的計算邏輯往往很復雜,再加上寬表的數據輸入是有大量依賴的,也就是說需要處理的數據量很大,在負載邏輯+大數據量的原因下,導致我們的寬表往往運行很慢,資源占用很多,尤其是重跑的時候。
穩定性不高
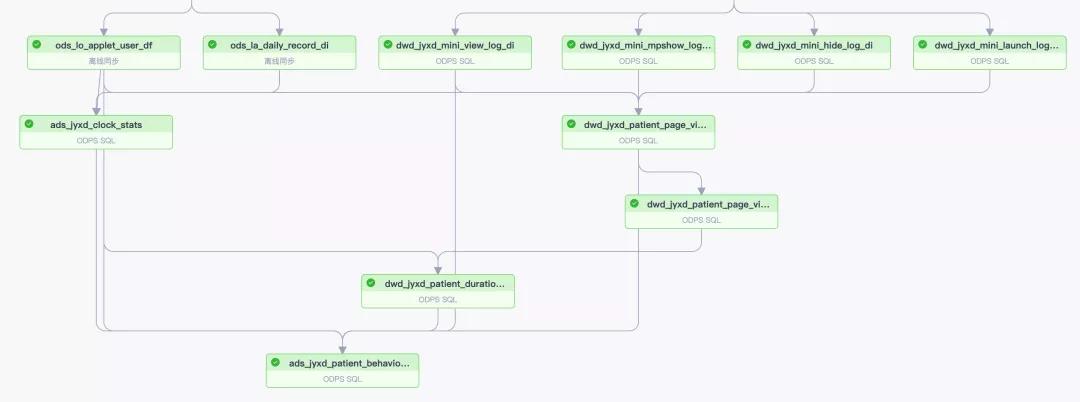
下面的最后一張表就是一張寬表,我們知道一個系統的穩定性是取決于最差的一個環節的,這就是短板理論也叫木桶理論,我們的寬表的穩定性也是很差的,這個主要是因為我們的寬表依賴太多,每一個表的不穩定性都會傳到到寬表。
假設 一張表依賴A B C 三張表,并且這三張表的穩定性是 1/m 1/n 1/x,那么我們的寬表的穩定性就是 1/m*n*x ,至于表的穩定性你可用它成功運行的次數/運行的總次數
如果性能不高和穩定性不高同時作用在一件事上的時候我們知道這其實是很致命的,例如你發現報表數據有問題,但是重跑需要幾個小時,哈哈!
開發難度大/維護成本高
我們說了基于寬表做報表開發才是正確的姿勢,但是寬表本身也是我們開發人員開發的,因為本身的邏輯很復雜設計的業務邏輯繁多,所以給我們的開發就帶來了挑戰,而且由于業務邏輯的變更我們也需要去維護著復雜的邏輯,例如每次都讓你在幾千行的SQL 里面加邏輯。
如何設計寬表
寬表的好處和不足我們都講了,也就是說寬表雖好,但是帶來的問題也很多,下面我們就看一下如何從設計的角度來避免寬表的不足之處
寬表到底多寬
開始之前,我們思考一個問題,那就是寬表到底有多寬,就想我們前面講分層的時候說其實我們不分層也玩得轉,早起的數倉就只有一層,現在我們考慮一個問題那就是寬表到底多寬才合適,其實你要把所有的數據裝進去也可以。
所以我們要思考到底多寬才合適的,前面我們介紹過數據域的概念,我們與其回答多寬這個問題,不如回答寬表都應該覆蓋哪些數據,但是這個問題也不好回答,但是我們可以反著思考,寬表不應該包含什么數據,這個問題很好回答,寬表不應該包含不屬于它所在域的數據,例如會員域的寬表只應該包含會員相關的信息,同理我們的寬表是針對某一個域而言的,也就是說它是有邊界的。
這下我們再來回答寬表到底多寬,只要不跨域,并且方便使用都是合理的。但是這似乎并不能解決我們上面提到的寬表的不足,只是指明了寬表的一個大致的方向。有了方向之后我們通過我們的設計策略就可以讓寬表瘦下來。
主次分類
主次分離,其實我們經常聽到的一句話就是做事情要搞清楚主次,我們看一下表設計的主次是什么,假設我們做的是一個會員域的寬表,但是會員域是還是一個比較大的概念,所以我們還要發掘出我們這個表的主題,例如我們做的是一張會員域下的會員基本信息寬表,那么我們專注的肯定就是基本信息,例如會員信息打通。當讓因為事寬表你可能還會冗余的其他信息進來,但是當這樣的信息越來越多的時候,我們這張表的主題就越來越弱,所以我們就需要做拆分。
拆分可以讓我們更加聚焦表的主題,對于數倉開發人員而言可以更好的維護、對于使用方而言可以更加清楚的理解這張表的主題。
冷熱分離
除了前面的主次分離我們還可以做冷熱分離,其實冷熱分離這個詞我相信你不是第一次聽到,但是怎么看這個事情呢,你想一下你在數據存儲的時候是怎么做冷熱分離的,這里也是同樣的理念。
假設我有一張寬表,里面有200個字段,有30張報表在使用它,但是我發現前面150個經常字段經常被使用,后面 50個字段只有一兩張報表使用到了,那么我們就可以做一個冷熱分離,將寬表拆分。
穩定與不穩定分離
其實前面的主次分離、冷熱分離都可以提高穩定性,但是前面我們不是為了穩定性分離的。
我們經常有這樣的寬表,它依賴埋點數據,但是我們的埋點數據的特點就是量大,導致計算經常延遲,那么我們的寬表就會受影響,從而我們的報表就受影響,但是很多時候你發現報表根本沒有用過埋點計算出來的指標,或者是只用了一兩個。那我們可以將其拆分,如果報表沒有使用到那就最好了,如果使用到了,那就后推,在報表層面上做關聯,這樣我們的埋點數據即使出不來,我們的報表數據還是可以看的。
總結
主要講解了一下幾個方面
- 為什么要建設寬表
- 寬表的不足
- 如何設計寬表
- 寬表到底多寬
- 主次分離
- 冷熱分類
- 穩定與不穩定分類
設計寬表的理論其實說白了就是一句話高內聚低耦合,當然這幾個字你在其他領域可能很熟悉了,但是這里你就好好思考一下才能想通,我一直新信奉的是一力降十會 一拙破萬巧 也就是說你要學會根本的東西,才能舉一反三破萬難。

























